


DataHem odyssey - the evolution of a data platform, part 2
Unified platform and data contracts

This is the second part about the evolution of MatHem’s analytical system. You find the first part here.
The third part will cover what was in our innovation roadmap before we were acquired by Oda and hence Mathem’s data platform team was resolved/re-organized.
2022-2023: Unified platform and declarative management
In the beginning of 2022 I got the opportunity to lead the data engineering team and we set a plan for how to best generate value from analytical data at scale. The value is generated when data is used for learning (by human or machine) and decision making that results in a better product or process, hence we want to enable the creation of data flywheels and get them spinning fast and reliable. The strategy to accomplish this was basically to:
Pivot the data engineering team into a data platform team and enable data product developers (software engineers, analytics engineers, data scientists, etc.) to autonomously build data flywheels (using reports, models, exports, etc.) - the only way to scale an increasing number of data producers, data consumers and data use cases.
Build a unified and opinionated data platform with limited but flexible components offering data input and output ports to support a majority of use cases. This reduces load on maintenance and ops, enables automation and let the whole team master all parts of the platform while freeing up time for innovation.
Leverage declarative management for (1) automation along the data life-cycle but also improve (2) data quality and (3) communication between stakeholders (i.e. producers and consumers of data)
Level up our software engineering best practices and improve internal developer experience and productivity
Obsess over data flywheels and platform adoption to deliver business value and establish self-sustaining business momentum.
Pivot and build a data platform team
The first we did was shifting from a data engineering team to a data platform team. This wasn’t done over night, but a journey that required us to both build the platform and act as a data engineering team during an interim period. You can read more about the reasons for pivoting in posts The Data Engineer is dead, long live the (Data) Platform Engineer and From pipelines to platform.

In order to accomplish that we had create bandwidth - add people. Looking back I see that we followed the pattern to build efficient teams described by Will Larson (Elegant Puzzle: Systems of Engineering Management)
Add people → Consolidate effort → Repay Debt → Innovate
The steps were executed with some overlap and not as a series of isolated steps.
Add people
During 2022 I got approval to grow the team from 3 FTEs to 7 which we did in less than a year - and what a year that was! We established a 5 step recruiting process covering screening (recruiter), personal interview (me), home assignment, tech interview (colleagues) and a personal interview (my manager) and recruited 2 new team members externally and 2 internally (analytics engineer and ml-engineer).
Growing from 3 to 7 in a short period uncovered (missing) processes and artifacts that work informally when you are three, but needs to be formalized, agreed on and documented when you are 7 in them team. But more on that later.
Except for the challenges that comes from quickly growing as a team we set a roadmap for our data platform. Simplified, that roadmap was to go from left to right along the data life-cycle and with focused efforts first repay debt and then innovate.
Consolidate efforts
Being only three FTEs we often worked on different projects/tasks but helped each other when needed. But being twice as many it felt like we started treading water and it pushed us to not only focus our efforts but also get to know each other better, hence we started working in pairs (with rotation), focus on epics and limit those to two and introduce on-call (rotating) to protect the team from ad-hoc requests or alerts. We had a number of Ways of Working sessions to iterate and iron out processes, ceremonies, documentation, responsibilities, etc. and continued to do so at least once every half-year. I was fortunate to have a team that was very open to test - evaluate - implement - iterate.
Repaying debt
The next step was to repay debt and the biggest one was to sunset the Azure pipelines and replace them with integrations directly from two of the most critical data sources to GCP. Another big debt was the Composer (managed Airflow service) transformation and validation jobs that we wanted to replace with a more user friendly and lightweight solution.
Sunset Azure
The first thing we did was to establish a direct integration from our Warehouse Management System (WMS) and ERP to ingest data without going through the complex Azure detour.
Warehouse Management System integration
Our WMS was a third party solution, Astro by Consafe, an application with SQL server as storage layer. We wanted to extract data with Change Data Capture (CDC) since the application layer couldn’t publish events. However, Consafe didn’t support that and they could only offer access to a replica DB or limited XML-files published on a SFTP server. I’m amazed how limited analytical and integration capabilities such central operational systems offers - huge market potential!
Hence, we created a serverless extraction service using FastAPI on Cloud Run orchestrated by Workflows and triggered by Cloud Scheduler and the pipelines were defined in Pulumi (IaC). The service extracted data by executing a query and publishing the records on pubsub as messages and then ingested into BigQuery with our common Dataflow job. Some extractions were executed as often as every 5 minutes resulting in 99% of records being duplicates and generating cost in both storage and compute. But with the vendor not offering better support we were stuck with it, at least the new integration was serverless and single cloud saving both money and ops. The solution has been extremely stable and any downtime is related to issues in the source system or the VPC.
ERP integration
The legacy integration with our ERP was done by Azure Data Factory querying the storage layer (MySQL DB) on a schedule via the integration runtime installed on the same instance. We wanted to replace that with CDC and for that we used GCP Datastream combined with Dataflow to ingest data into BigQuery. This was really simple to setup, the biggest challenge was that no developer team took ownership of individual tables as it was a legacy monolith.
Sunset Composer
Given the challenges identified with Composer and the fact that we mostly did streaming ingest we decided to replace it with a serverless DBT service and well defined CI/CD process, environment and tooling to create a good developer experience for our stakeholders.
The composer tasks that we needed to replace to migrate to our DBT service were:
Transformation/modelling jobs
Data quality checks
Data export jobs
The first two were straightforward and DBT offered a superior developer experience for our data scientists and analytics engineers to define models and transformations in SQL.
DBT data exports
When it comes to the data exports we also wanted to shift the ownership to users and enable them to easily create exports needed directly in DBT. Sinks we had to support were external BigQuery projects, Google Cloud Storage (GCS) and AWS S3.
There is an export functionality in DBT/BigQuery to output data to GCS that was useful and solved several of our use cases directly, but we also needed to export JSON-files to AWS S3 and for that we built an event-driven workflow with a cloud function that transferred the files in an authenticated manner. One challenge was that it may output multiple files (not configurable) when the receiver wanted only one file, in order to set up an event triggered workflow that waits for all files we resorted to an old but well tried Hadoop/Spark solution - the _SUCCESS file, i.e. let the DBT export macro finish by exporting a _SUCCESS file to the same folder and listen for that file to trigger the workflow. The _SUCCESS file could contain metadata if we wanted to add specific configuration for export jobs, but we never got that far.
The solution did the job and made it a lot easier for data scientists and software developers to take on ownership of exports.
Developer experience and medallion architecture
This section probably deserves its own post (or several) with input from the team that has much deeper knowledge of the exact solution, but I decided to at least give a summary/overview of the setup.
We set up DBT with three different DBT projects, each owned by its own team. The code was managed in the same repository but the projects lived in different folders with different code owners. We also took the opportunity to switch from one GCP-project used for both storage and compute to multiple projects.
For compute we created separate projects for DBT and Looker to set different quotas and make sure they were not impacted by adhoc user queries.
For storage we implemented a medallion architecture with one GCP project for each layer (Bronze, Silver, Gold and experimental).
In addition we also added a dev environment (a separate GCP project) that let each developer work on their branch without interfering with other DBT users.
The data platform team owned the Bronze and Silver layer while Analytics engineers owned the Gold layer and data scientists owned the experimental layer. All the transformations and models where initially done manually, but that is something we decided to automate with configurative management when we reached the innovation stage.
The DBT service was built and deployed on merge to main and running with a FastAPI wrapper on cloud run. The service infra and associated services (scheduler and workflows) were configured with pulumi. We initially monitored it with Google Cloud Monitoring and later complemented it with Elementary as a result of a successful hackday project. The elementary reports and alerts were published on slack channels, one for each dbt project since they had different owners.
There were some pain points we addressed in the innovation stage that were related to cost and data freshness in the development environment, refresh triggers and avoiding full refresh in upstream projects (a really nice macro created by the team).
Innovate
With the bandwidth in place, a consolidated and coordinated way of working and much of the tech debt repaid - it was time to innovate! The innovation was primarily focused on pivoting into a data platform team and deliver a data platform that enables stakeholders to be autonomous developing data products. The plan to accomplish this was to build an unified and opinionated data platform, leverage declarative management (a.k.a. data contracts) and level up our tooling and software engineering practices.
Build a unified and opinionated data platform
The first key component to scaling value is to ensure you have a small set of core components, i.e. a unified architecture. These components are put together to form a loosely coupled but unified approach to support multiple and well defined producer and consumer patterns. Together these components form a timeglass shaped system with a limited set of data input and output ports to offer flexibility and with components in between being the same to keep down operational cost and maintenance but also make it easier for the whole team to master all parts of the data platform regardless source or destination.

The data input ports were either push (CDC, Event or File) or pull (fetch from API or Query DB) but they were all built as serverless (Cloud Run/Functions) or using managed service (Datastream) and publishing the data on pubsu. For example if a file is uploaded to GCS then it trigger an event to execute a cloud function that reads the data and publish each row as a message on the pubsub topic. With these input ports we covered pretty much every use case we had.
The ingest component is a streaming architecture built on Dataflow that is processing data from pubsub and writes to BigQuery. Read One Streamprocessor to rule them all or from pipelines to platform for more details.
The transform is a fastAPI application on cloud run that executes our DBT models according to a schedule defined in the data contract mentioned earlier. This is also part of a review process and with checks, test environment, CI/CD etc. See the section about sunset composer and configurative management for more details.
The export is also a service provided by the data platform team where the logic is defined in DBT and the actual export is event-driven with the help of GCS, cloud functions and workflows. See the section above about dbt data export for more details.
Ingest, transform and export all follow the same idea of enabling stakeholders to be autonomous and own the business logic and data quality while we provide the systems, tooling and support to offer a great developer experience and an efficient process.
In addition to the components of the data platform we also started to harmonize the development and deployment of ML-models to run on a common ML-platform to make it easier for more platform engineers to operate the ML-models (reducing single person dependency) while giving our data scientists a better developer experience building ML-models.
Visualizing the unified platform architecture it looked something like below which is quite a change from the Batch BI architecture we had 6 years ago.,
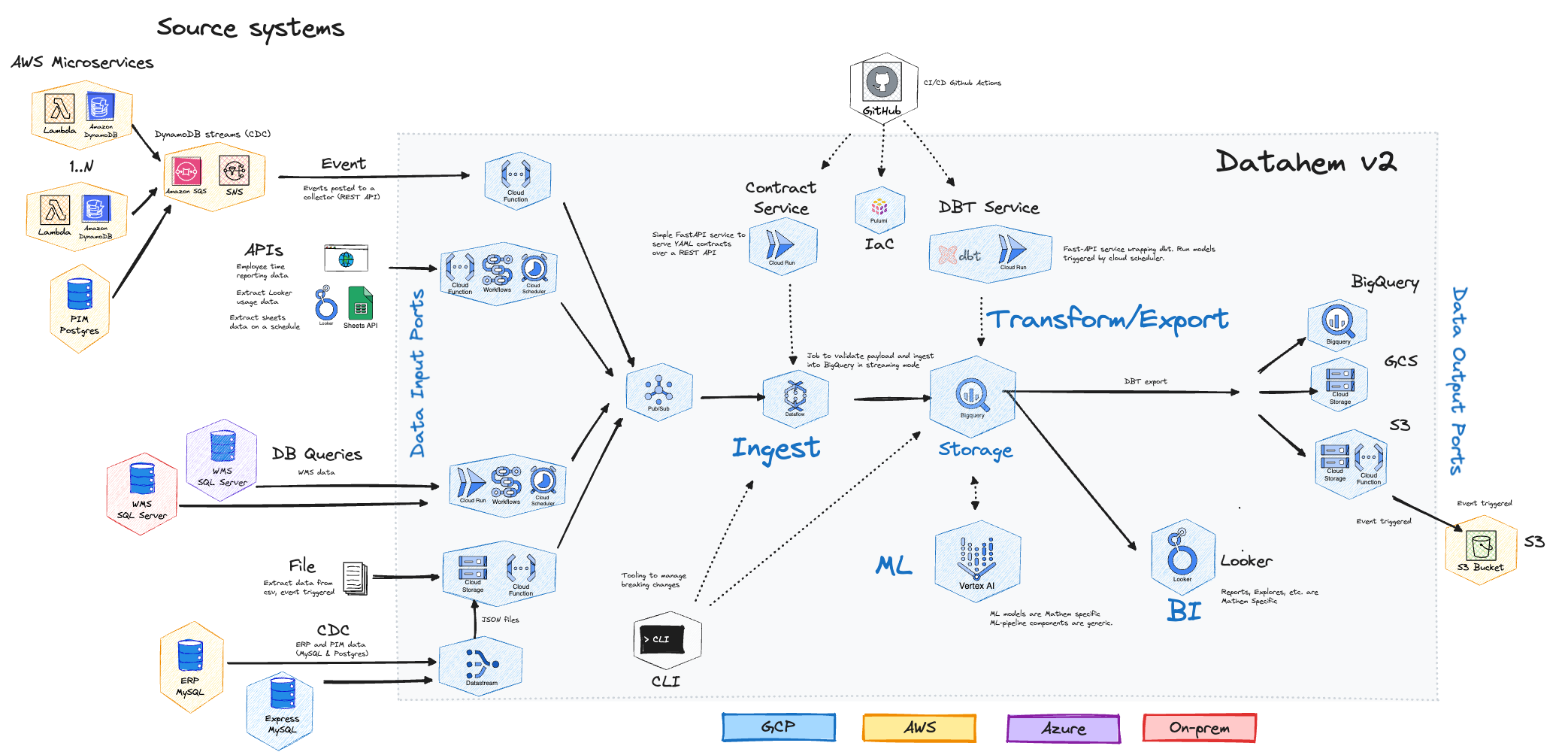
Some general guiding principles we followed designing the solution:
We prefered to build on top of serverless services to minimize operations while being able to scale and keep down costs.
We also took a build + single vendor (GCP native services as they have a strong end-to-end service coverage) approach over buying best of breed as it provided us comprehensive integration, good security and user management, high efficiency and low costs.
We also preferred code over no-code solutions. No-code may be nice at point-in-time implementations but usually comes with a painful maintenance/migration/customization cost.
Declarative management
The second key component to scale is declarative management, a.k.a. data contracts. It not only help addressing data quality, observability, security, governance and semantics, it also enables automation and communication, two areas that I think aren’t emphasized enough in the current data contracts hype that is very focused on data quality.
The data contract
At Mathem we decided to replace our protobuf contracts with YAML that is much easier to read and understand for someone not used to protobuf. Also, YAML is relatively easy to parse and generate files in other formats (proto, json-schema, avro, etc.) if needed.
The contract consists of different sections. The example contract below is related to product proposals submitted by Mathem customers that help us update the assortment that we keep in stock. As you can see it defines both the source (DynamoDB stream) and target (BigQuery tables) where we also can define what kind of models we want to build in our silver layer (we have a medallion architecture) to be ready for downstream consumers. It also defines ownership and makes it clear what squad that owns this data asset and where you find the repo of service that is the origin of the data. We also have the schema and some optional sections not shown. The schema follows the BigQuery schema definition as that is our primary target destination and to the right you also see the replica table created from this contract.

The process
The process for creating and publishing a contract is a vehicle for both communication and validation which is essential in order to remove the data engineer as a bottleneck. When a data producer makes a PR of a data contract a number data consumer teams will be notified for a review. The dialog is about things like descriptions, data types and whether a field is required or nullable. But also what fields constitute primary and sort keys and what kind of models consumers want generated. The PR will also trigger a number of validation checks that not only check if the contract is valid according to the data contract specification but also if a sample of payloads pass the contract verification.
When the PR is approved and pass all checks it gets merged and the data contract service (fastAPI on Cloud Run) is updated accordingly and our Infrastructure as Code (Pulumi) will set up the corresponding staging tables in BigQuery. The merge will also generate a PR in the DBT repo to generate the silver layer models defined by the data contract.

There is also a lot of dialogue between team members within the data producing squad and the contracts are not only valuable for the analytical system as we’ve seen it is a great tooling also to verify the data quality in the operational system as many of our micro services use a schemaless storage layer (dynamodb).
Software engineering best practices
In addition to iterating on Ways of Working (WoW) sessions, data platform team handbook, book club, tips & link sharing channel, hackdays, lunch and learn sessions, etc. to improve our collaboration and learning we also implemented a number of tooling and best practices to improve our standards. Some examples include:
“Monorepo”
Mathem’s tech organisation became very micro services oriented over the years and each service had its own repository. This created a culture with many repos (when I left there were over 1000 repos in Mathem’s org) and it was also reflected in how we organised the code in my team with a growing number of repositories. In one of our WoW-sessions we decided to consolidate our component repositories into a data platform “monorepo”. We experienced that it made collaboration and development easier and more efficient.
Pre-commit hooks
We started using pre-commit hooks (linting and formatting) to identify issues locally before requesting code reviews. That reduced issues in code before code review, allowing a reviewer to focus on the architecture of a change instead of wasting time on trivial issues.
PR monitoring slack channel
A slack channel containing messages with open PRs and their current status. As soon as a PR was merged the corresponding message was removed from the slack channel.
Pulumi
We also started to use Pulumi as IaC for everything new that we built, we choose Pulumi as we liked the declarative definitions with imperative language (Python) and the up to date native libraries. We also added a scheduled refresh job in Github actions to make sure there is no drift. Pulumi is the only third party service we use in our data platform and it is great as it basically is a CLI running as part of our CI/CD and the pulumi service only contains the state of our resources, it doesn’t have access to any resource or data inside our GCP projects.
CLIs
We also built a CLI to help with repetitive tasks, it could be anything from creating models from contracts, re-deploying pipelines or run backfills. We also saw other teams building CLIs to improve the experience, one such example was a CLI that could generate 80% of the data contract from the data classes in C# micro services, extra handy when an object contained a lot of fields. I would say that kind of tooling can be the catalyst to really lift adoption, it is easy to focus on the core and complex tech (the engine) and forget about the smaller parts (the oil) that reduce friction and improve adoption.
Github - actions, projects and pilot
Another thing we did to improve our developer experience and flow was to make the most of Github and reduce context switching. This included:
Cloud build → Github actions
Executing the CI/CD in Github rather than Cloud Build was a really nice experience, staying within the same console despite occasional outages at Github and previously being a fan of Cloud Build.
Jira → Github projects
Mathem used Jira and the initial Github projects release was quite lame, but with the new Github projects release and not requiring all bells and whistles in Jira we found Github projects suiting us better. It was more lightweight and more tightly integrated with issues, labeling, etc. Give it a shot if you haven’t already tried it.
Code pilot
Mathem’s tech department was pretty slow adopting code pilot, it was mostly the data platform team and the operational infra team that pushed for it. However, we found it helpful enough to justify the expense. We also started trying out Google Duet as we could use it both in BigQuery SQL console as VS Code, our initial experience was that the results were pretty similar.
Flywheels and adoption
As any platform the key metric is adoption and we saw a huge boost of that when launching DataHem version 2. Compared to version 1 I would say that the adoption was 10x and definitely worth the investment.
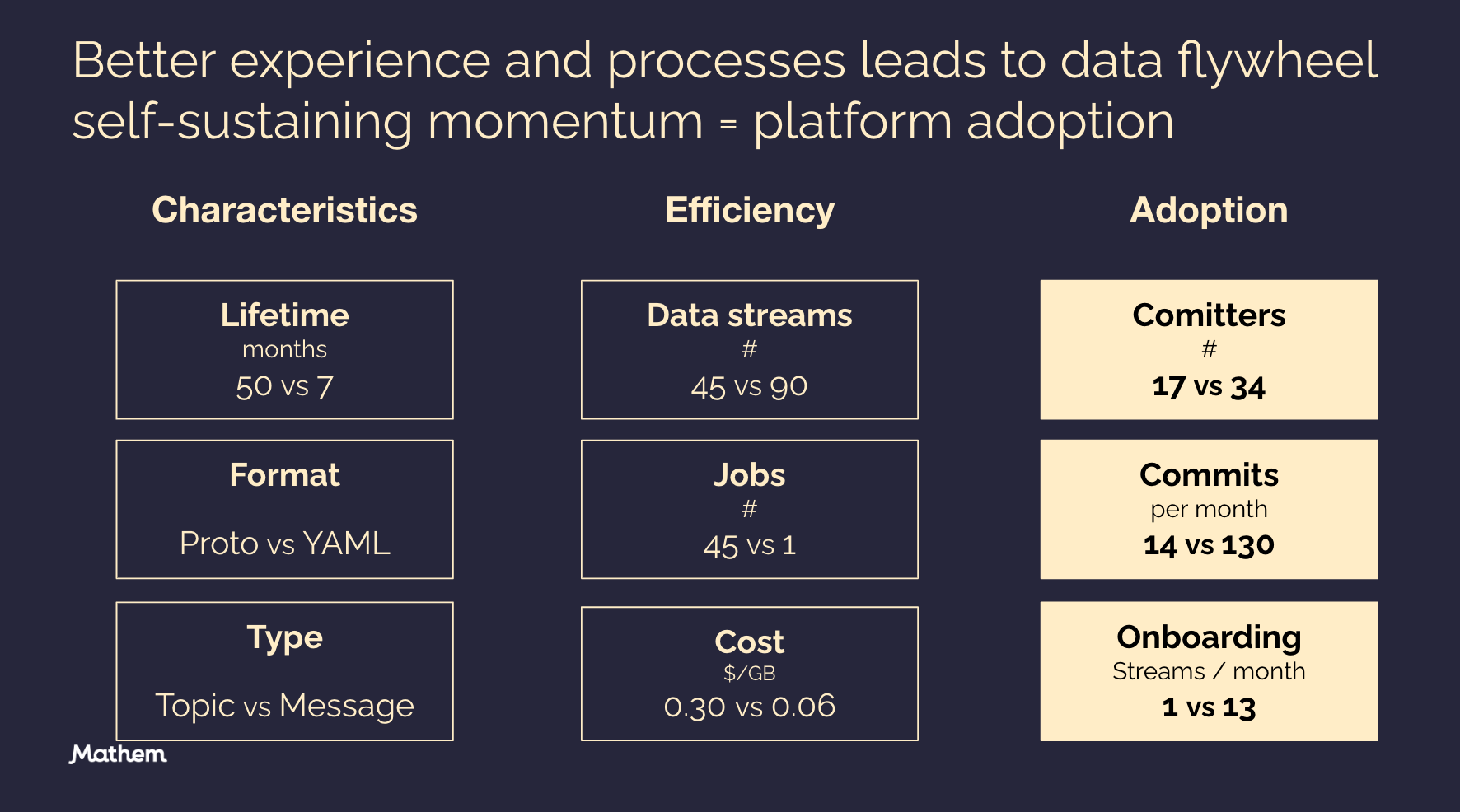
After running DataHem v2 for 7 months we got twice as many data streams onboarded compared to version 1 while running only one job instead of 45 which not only reduce the maintenance and operational overhead but also cost due to much better resource utilization. But the most positive of them all is the adoption of the solution amongst our data producers and consumers. We have twice the number of committers, the activity is 10x (!) and we have onboarded one stream every second workday in average. However, as much it signal success for the new solution and data platform ways of working, it also tells a story about how an inadequate solution slows down adoption and that you will never reach flywheel self-sustaining momentum unless your stakeholders are offered a great experience and efficient process.
We even started to categorize requests and key initiatives in flywheels along with the domain that requested it (in a matrix) to get a more holistic overview in our roadmap planning and being able to make focused efforts. We usually started with the smallest flywheels that exist on the left side (operational analytics and reports) of the data life cycle and gradually move to the bigger and more complex flywheels to the right (Exports to 3rd party and ML).
I'm committed to keeping this content free and accessible for everyone interested in data platform engineering. If you find this post valuable, the most helpful way you can support this effort is by giving it a like, leaving a comment, or sharing it with others via a restack or recommendation. It truly helps spread the word and encourage future content!
Nice writeup! The YAML -> Pulumi -> BigQuery is the same as the example I created for my book, so it's interesting to read about it in production (and again, interesting that similar ideas are created independently around the same time).
You mentioned that you used the medallion architecture, and the data platform team owned the Bronze and Silver layer. Were the data contracts you describe used to present the data to the analytics engineers working in the Gold layer?
Were data contracts also used as the data was ingested from the source systems (events, DB queries, files, CDC)? And if so, how did you encourage adoption there?