
DataHem odyssey - the evolution of a data platform, part 1
A retrospect of Mathem's analytical system

After six years at Mathem I find it timely to share a retrospect of MatHem’s analytical system. It is a story with 4 chapters that illustrates the journey from an entrepreneurial startup with a “one-man data team” to a scale-up with a data platform team.
This post covers the first two chapters:
2018: Batch BI
2019-2021: Streaming ingest & data activation
2022-2023: Unified platform and declarative management
Learnings made and what would have been next steps
I’m confident I have forgotten some things and may remember some things wrong, but in overall this is the story of MatHem’s data platform named DataHem (a Swedish play with words, Data = data, hem = home, also Mat = food/groceries). For those who aren’t familiar with Mathem it is Sweden’s #1 online grocery (with home delivery).
2018: Batch BI
When I joined Mathem in the spring of 2018 the data team consisted by 2 data scientists and 2 data engineers. The data scientists and data engineers were divided in pairs working on different strategic projects that could take more than a year to complete. One of the data engineers was also responsible for the data warehouse and the data pipelines (~50%). There was also one BI developer in the e-commerce team that was responsible for PowerBI and a consultant that maintained QlikView.
Azure and duplicate Business Intelligence
At that time our most important data sources - the ERP and Warehouse Management System (WMS), were hosted by the Swedish cloud provider Redbridge (Binero). That was also the case for QlikView. The data warehouse lived in Azure and data was Extracted via an integration runtime instance and then Transformed and Loaded on a schedule by Azure Data Factory. It was all batch and since records could be modified more than once between two runs we didn’t get great granularity or completeness of data. The transformation logic was defined directly in the Azure Data Factory console. Since we had two BI systems (PowerBI and QlikView) the business logic was implemented twice and hence caused a lot of extra work. The BI-tools were also connected directly to the source systems for some queries, which put extra load on production systems.
Identified pain points:
No CI/CD and bad data granularity
Direct connections put extra load on the production system
Duplicate implementation of business logic in BI tools

AWS micro services as source system
A few years earlier, Mathem had started building a new technology platform based on micro services running on AWS and the number of services started to become quite a few and the long term objective was to replace and sunset the legacy ERP. The services were mostly built in C# or node.js, executed on lambda and with dynamoDB (NoSQL) as storage layer. This is something completely different from a monolith with a RDBMS and the BI-tools didn’t support that kind of direct connection. A few (the 3 most important ones) were synced either via the ERP or custom integrations to the data warehouse in Azure.
The interesting thing here is that while a storage layer such as DynamoDB is extremely reliable, flexible and offering fast responses it is hard to do aggregate analysis on top of it and the flexible schema often results in stale columns and broken schemas (as there is no schema). Also, the data is defined as JSON objects and nested and/or repeated data is quite common which many data warehouses don’t support natively. All of this creates a great incentive for the developers to connect the operational micro service to the data platform to get a SQL lens and immutable log of their own data. But more on that later.
It became obvious that we had to build a data platform that not only made data from the micro services available in the analytical system but also make data available for data activation. The data activation part was emphasized as one of the strategic data science projects was replaced by a third party service that needed input from the data platform to deliver demand predictions and generate purchase proposals of supplies that not only saved a lot of time but also product waste. We also wanted to avoid BI-tools to connect directly with production source systems.
Identified pain points:
No support to analyze data from micro services
No support for data activation
It became obvious that we had to build a data platform that not only made data from the micro services available in the analytical system but also make data available for data activation.
Custom built digital analytics solution
At the same time the e-commerce team was looking at different options for digital analytics since the standard Google Analytics plan wasn’t enough (Mathem exceeded the free quota by 10x). Before joining Mathem I had the position as global head of digital analytics at Tele2 and brought with me not only the good experiences I had from BigQuery but also the limitations of the Google Analytics (premium) BigQuery export capabilities.
However, I had experimented a little with Apache Beam and Google Dataflow on my spare time and found it quite easy to piggyback on the existing Google Analytics tracking and use Dataflow to process the data and ingest into BigQuery in real time with a more user friendly schema and at a fraction of the cost of GA 360 (premium). Also, BigQuery proved to be extraordinary good for analysis of nested/repeated data that is quite common for events (ex GA events), something that is a bigger challenge in more tabular oriented data warehouses. So, this is what we implemented at Mathem to complete the GA standard implementation, not knowing that it was the embryo of DataHem.

2019-2021: Streaming ingest & data activation
So we had a situation with a growing number of micro services passing around events and a storage layer containing semi-structured data (JSON) and not easily made available in the existing BI-systems (two is one to many). At the same time we had a solution that ingested semi-structured events (JSON) from the front-end in real time. What if we could tweak it to be more generic and configurable and use it to ingest data from the micro service back-end?
Streaming Ingestion
Hence, with some initial help from the infra team and CTO to set up the dynamoDB streams (Change Data Capture) and send the data to a collector (cloud function) on GCP, I developed a PoC to validate and process the data with a generic Dataflow job that also ingest it into BigQuery. In order to make the Dataflow code generic but configurable and guarantee data quality and enable controlled schema evolution I introduced data contracts defined as protobuf (much better support of JSON than Avro had at the time) and made great use of dynamic messages (supported in Java). It has later been claimed by others that they have invented “data contracts”, we don’t, the idea has probably existed for decades but perhaps not referred to as data contracts, we got a lot of inspiration from the Kafka schema registry as we built a solution on streams.
For each micro service we wanted to connect we would create a data contract (proto file) and deploy a dataflow job. Hence, we could deploy and evolve data streams isolated from all other streams. The protobuf schema was defined by the developer teams, but it was a bit cumbersome as the operational system didn’t make use of contracts at all and protobuf experience was limited. Thus, the jobs required some infra (1 instance per stream) and cost grew linearly with the amount of streams, but they were very resilient and reliable to operate. The data was ingested in real time and with a native BigQuery schema that matched the data objects (no VARIANT or SUPER data types) which made it possible to support use cases with low latency requirements. DataHem version 1 was born. But we identified pain points we wanted to address later:
Too much infra/cost per stream as the number of streams grew.
No (declarative) Infrastructure as Code tool/service. Infra was provided either through console or with imperative scripts executed by cloud build.
Protobuf was too difficult/complex as data contract format to enable data producers setting up data streams autonomously.
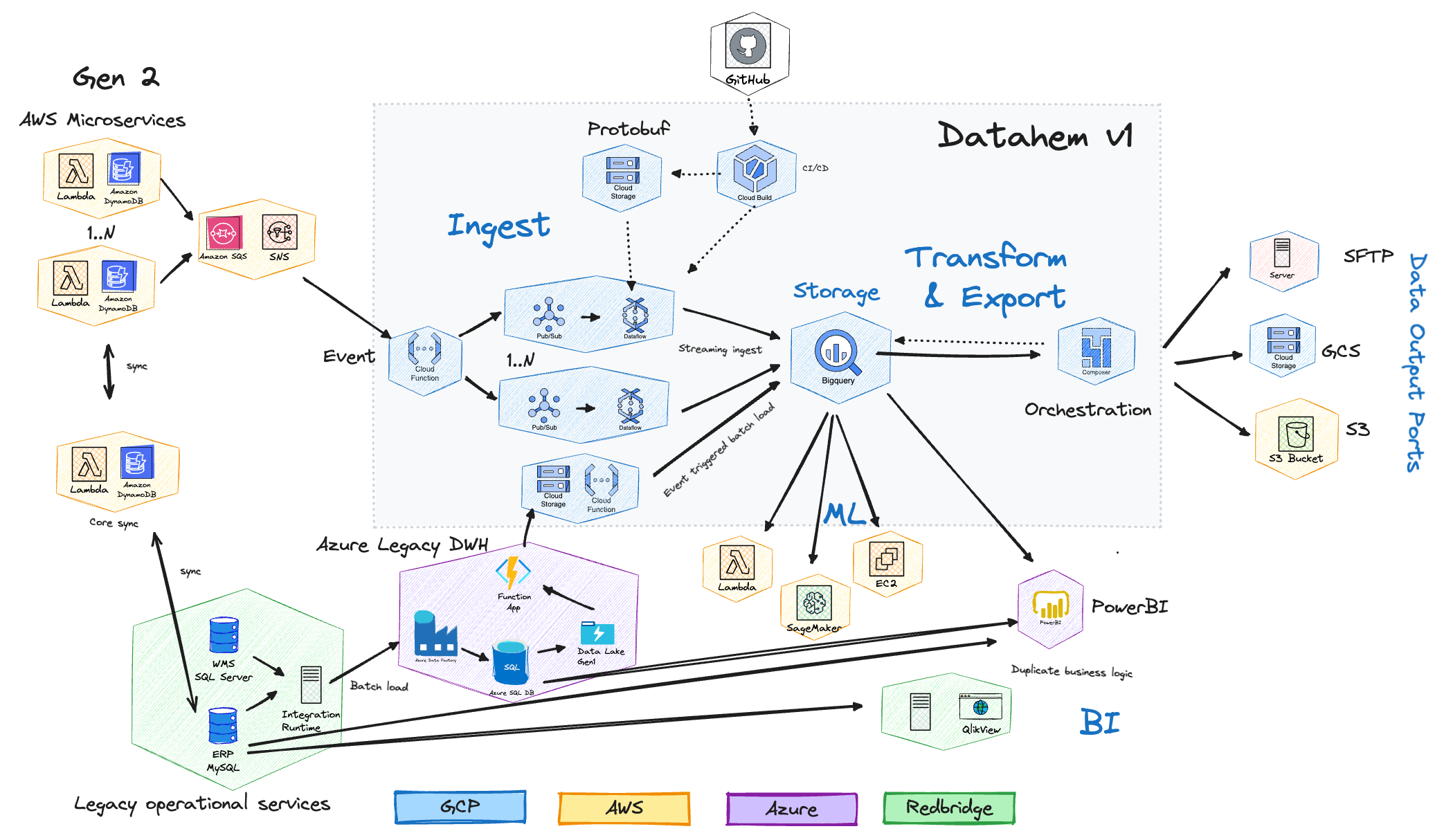
Transformation and activation
Now we got data ingested from the micro services into BigQuery, but we also needed to run transformations within BigQuery to prepare data and model it for analysis and reporting. This was done by setting up Composer (managed airflow) to orchestrate BigQuery transformations and we finally got version control on the SQL, previously models were defined directly in the BigQuery console. But Composer was cumbersome for analysts and data scientists to use and the data engineers were often involved to deploy the code. Composer was also used to activate data either as extracts back to operational micro services, third party systems or serving data to train ML-models. However, we identified quite a few pain points in the transform step to address:
Composer was too complex and slow to work with to enable analytics engineers and data scientists creating models autonomously
Created a lot of noise in the error reporting with frequent Kubernetes related errors/warnings that didn’t affect the uptime of Composer
Unreliable, it occasionally failed tasks for no apparent reason
Used for compute (anti-pattern)
Cost money even at low/no utilization
Multi-cloud batch jobs
The progress was great, but we were still dependent on the Azure batch jobs to get data from our WMS and ERP into BigQuery. The quickfix was done by adding an event driven pipeline that used functions to move data between blob storages and finally upload data into BigQuery. It worked (most of the time) but had many moving parts spread across multiple clouds and hence really hard to debug.
Identified pain points:
Many moving parts increase risk for failure, harder to debug, more costly to operate and maintain, harder to learn the whole pipeline for new team members
Business Intelligence
During the second half of 2020 we hired data analysts and initiated the work to replace PowerBI and QlikView with Looker as our BI tool and a lot of business logic was defined with LookML. It turned out to take almost 3 years to complete that migration. Pain points:
Maintaining 2 BI tools while migrating business logic and users to a third tool and new tool is a delicate project.
Implementing all the modeling and logic in LookML was slow and complex, hard to overview and created strong lock-in effects.
Machine Learning
We had a few ML-models running in production, but all of them deployed in different ways and using different services for execution and hence hard to maintain and operate and few knew how those worked and could fix them if needed.
Summary
Entering 2022 we had plenty of pain points to address and it was apparent that data engineers were involved in so many parts along the data life-cycle that we blocked other stakeholders dependent on us to get their work done. But we also had a good idea of how to tackle that, it was time to reorganize and build DataHem version 2 which I will cover in part 2.
I'm committed to keeping this content free and accessible for everyone interested in data platform engineering. If you find this post valuable, the most helpful way you can support this effort is by giving it a like, leaving a comment, or sharing it with others via a restack or recommendation. It truly helps spread the word and encourage future content!
Interesting write up, thanks for sharing!
That Streaming Ingestion system with protobuf and generic Dataflow is very similar to something we created (ours was Avro and generic Dataflow!). We called it the Data Platform Gateway (DPG). We avoided the infra costs by having one stream, but that made the stream very difficult to use, and also made the autonomy problem worse.
Our next iteration became what we called data contracts (as compared to the DPG, which was mostly "just" schemas).
I find it interesting that at similar times different organisations were treading similar paths almost in isolation. Well, maybe not isolation, since there's probably loads of ideas and trends we were aware of that were influencing us both in similar ways, even if subconsciously. But I think one of the great things we have today is the low barrier entry to sharing ideas, and hopefully that's accelerating how things change for the better in our industry.
Looking forward to the next post!
Very interesting read. You could just not imagine the pain with migrating BI-tools. Isn't that supposed to be "easy"?!