
One StreamProcessor to rule them all
Dynamic multi-message streaming ingest with Apache Beam and Dataflow

The last 6 months my team at Mathem has gradually pivoted from a data engineering team into a data platform team. The reasons for that is well described in a separate post. Two important components to succeed with this journey are data contracts and a unified architecture. I will cover the parts of our architecture more in detail but thought I would share a 10k feet picture of how it works as Apache Beam is a central piece in our architecture and the Apache Beam 2023 Summit took place earlier this week (looking forward to videos from that if released).
Data contracts is key to automate as much as possible while improving data quality and shift ownership towards data producers. However, the actual implementation (the use of the contracts) is done in a streaming Beam job running on GCP Dataflow and in DBT to create data warehouse models. We offer different data input ports (REST api, pubsub, file, etc.) and all data is streamed through the mentioned job that we call StreamProcessor (will be open sourced, you can preview the code here).
We are in the middle of migrating legacy data streams to StreamProcessor since it offers a multitude of benefits. There’s an old and long post about our legacy streams, but to briefly describe it, those are built on a generic template but reference a specific proto at start of the job to correctly serialize the data and apply some simple transforms before ingesting to the specified BigQuery table, i.e. one legacy data stream equals one dataflow job.
The StreamProcessor solution
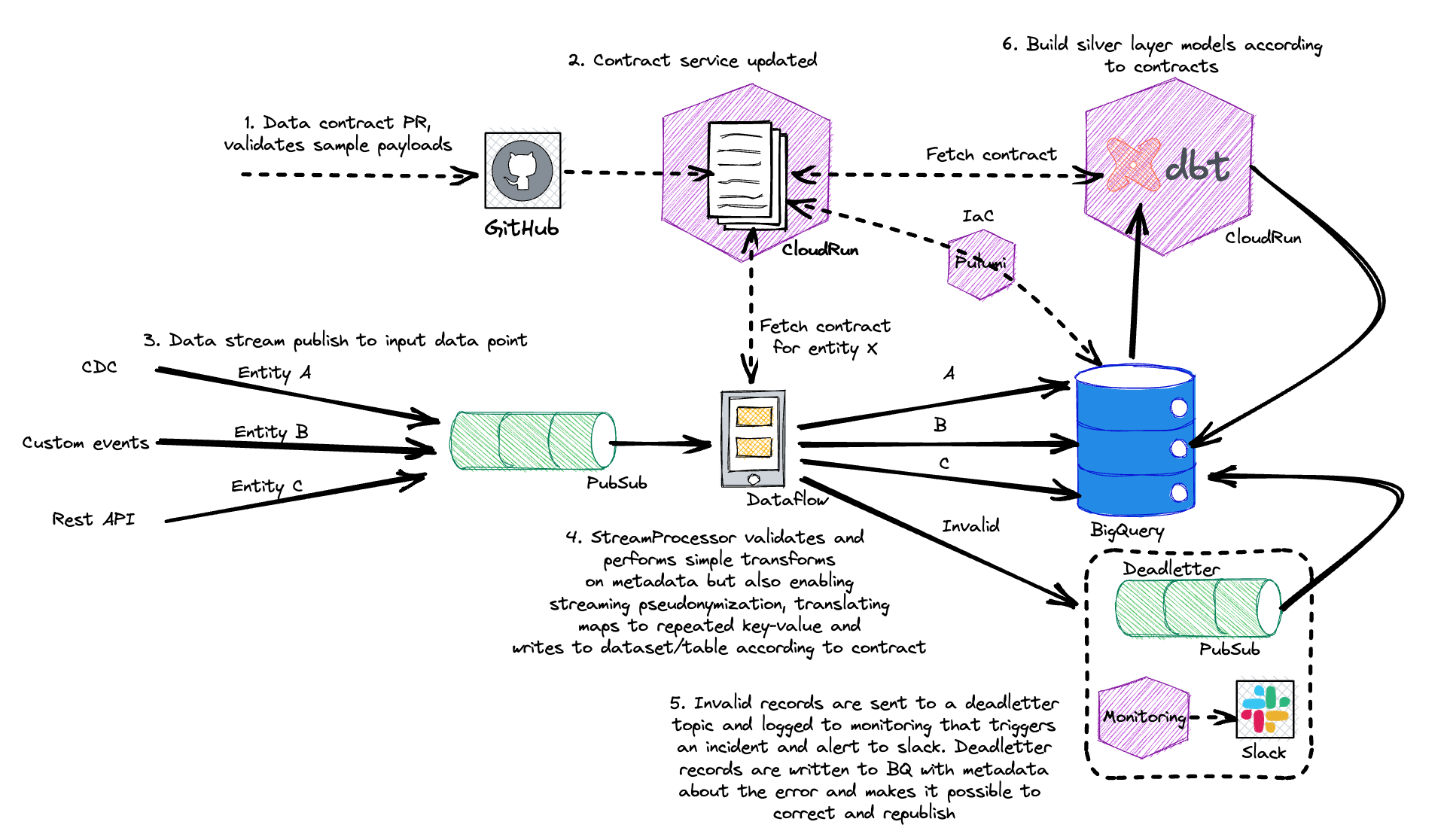
The new dataflow job (a.k.a. StreamProcessor) look up schema and meta-data (on message and field level) from our contract service that is a custom built cloud run application and cache the schema in the dataflow job (expiration is configurable but default is 5 minutes). This means that we can update the schema at any point in time without having to redeploy StreamProcessor.
Also, the lookup of a data contract is based on attributes in the pubsub message and StreamProcessor has a custom coder that enables different kind of messages being being passed between steps and workers and processed without being separate pcollections, hence the DAG is straightforward and doesn’t change (i.e. we can update the job if needed without downtime) and we can process multiple data streams in the same dataflow job, adding and removing data streams on the fly.

This results in one dataflow job regardless the number data streams which is great in terms of better utilization of compute resources (i.e. cost) but also measured in maintenance and operations when we can consolidate 50 jobs into 1.
The data contract contains schema and meta-data (see below) that is used to both parse and serialize the message into a Beam Row with options on both message level and field level. The schema is expressed as ZetaSQL (i.e. BigQuery schema) and the metadata contains everything from producing system, owners, target dataset and table, materialization options, update frequency, primary keys and sort keys. Some metadata is primarily used by StreamProcessor for ingest into our bronze layer while others by our custom DBT cli to move data downstream through the medallion arch.
One example of such metadata are the target dataset and table that is translated into a beam row message option and used in the BigQuery.IO write step to write messages of different types to different BigQuery datasets and tables. We also support options on field level that we can use for tokenization of sensitive data but also data quality validation.
Below you find an example of how a data contract may look like, I will write a separate and detailed post about data contracts later. But the contract such as the one below is created by the data producer (i.e. our squads) and they have even built some internal tooling to generate data contracts from their service definitions.
version: "1"
entity: deliverytime-service-CapacityCounterTopic
valid_from: "2020-05-19"
endpoints:
source:
provider: dynamodb
target:
friendly_name: delivery_capacity_counter
models:
- type: timeseries
cadence:
- daily
- type: latest
cadence:
- daily
ownership:
squad: DOF - Delivery Offering
repository: https://github.com/mathem-se/deliverytime-service
slack_channel: "#squad-dof"
product_area: Fulfillment
description: |
Limits 1.0: Capacity decisions for stores and slots.
Capacity for a store is found by looking at the records with DeliveryTimeScope=DeliveryTimeStore.
The Id of these records will be on the format 0S{{StoreId}}.
The store is full if either the ExternalCount or InternalCount is above the MaxOrderLines.
Capacity for a slot is found by looking at the records with DeliveryTimeScope=DeliveryTimeSlot.
The Id of these records will be the delivery time definition id.
The slot is full if either the ExternalCount or InternalCount is above the MaxOrders limit.
Timeseries can be built using LastModified.
schema:
primary_keys:
- Id
- DeliveryDate
sort_keys:
- LastModified
columns:
- name: LastModified
description: "Lastmodified as timestamp"
mode: REQUIRED
type: TIMESTAMP
- name: Type
description: "Type of item"
mode: NULLABLE
type: STRING
- name: ExternalCount
description: "External count"
mode: NULLABLE
type: INTEGER
- name: StoreId
description: "Id of the store"
mode: REQUIRED
type: INTEGER
- name: PotPercentage
description: "Pot percentage"
mode: NULLABLE
type: FLOAT
- name: DeliveryDate
description: "Date of Delivery"
mode: REQUIRED
type: TIMESTAMP
- name: Id
description: "Id"
mode: REQUIRED
type: STRING
- name: DeliveryTimeScope
description: "Delivery Time Scope"
mode: REQUIRED
type: STRING
- name: IsFull
description: "Is Full"
mode: NULLABLE
type: INTEGER
- name: MaxOrders
description: "Max Orders"
mode: NULLABLE
type: INTEGER
- name: SdlReservedOrderLines
description: "Reserved Order Lines for SDL"
mode: NULLABLE
type: INTEGER
- name: MaxOrderLines
description: "Max Order Lines"
mode: NULLABLE
type: INTEGER
- name: InternalCount
description: "Internal Count"
mode: NULLABLE
type: INTEGERSummary
Developing and operating streaming data ingestion jobs using Apache Beam and Dataflow has been a great experience and I feel that both don’t get the cred and recognition they deserve, especially since Apache Beam is open source and supports multiple languages and runners (and hence cloud providers). If you liked this post (I know it was mostly a teaser) then please subscribe for upcoming posts covering the solution more in detail.