
The Data Engineer is dead, long live the (Data) Platform Engineer
Wait, isn't data engineer the hottest job in the 2020s?

I'm committed to keeping this content free and accessible for everyone interested in data platform engineering. If you find this post valuable, the most helpful way you can support this effort is by giving it a like, leaving a comment, or sharing it with others via a restack or recommendation. It truly helps spread the word and encourage future content!
11 years ago Harvard Business Review dubbed data scientist the sexiest job of the 21st Century and I was one of those quickly jumping on that train. But quite soon I realized that something was missing - data infrastructure - and data scientists don’t build or maintain that and provide little value without it. Hence, I jumped off the data scientist hype and made a bet on the lesser known role as data engineer. Fast forward 10 years and now the data engineer is regarded as the hottest job in data. So why do I say that the data engineer is dead and a new breed is the future?
I won’t go deep into every section as there is plenty of great content I recommend for anyone who wants to dig deeper.

Data engineer and data engineering
Let’s start with a definition of the data engineer and data engineering. One of the best books on data engineering is “Fundamentals of Data Engineering” by Joe Reis and Matt Housley (make sure to follow them) and they use the following definition.1
Data engineering is the development, implementation, and maintenance of systems and processes that take in raw data and produce high-quality, consistent information that supports downstream use cases, such as analysis and machine learning. Data engineering is the intersection of security, data management, DataOps, data architecture, orchestration, and software engineering. A data engineer manages the data engineering lifecycle, beginning with getting data from source systems and ending with serving data for use cases, such as analysis or machine learning.
(Joe Reis and Matt Housley, Fundamentals of Data Engineering)

This definition emphasizes the ingest, transform, store and serve data (the data engineering life cycle) with some undercurrents cutting through the steps. I don’t disagree, I think it captures most of what data engineering has centered around historically. But role definitions are hard and often subject for discussions (as you likely will notice in this post), but the intention of this post isn’t really about role definitions but how and why the actual work description and responsibilities may change for many data engineers coming years.
Data engineer burn out
So the data engineer role is in high demand, but surveys show that the job isn’t as rosy as expected as surveys suggests an overwhelming majority are burned out and calling for relief.2
The data engineers surveyed identified significant sources of burnout including:
Spending too much time finding and fixing errors
Manual, repetitive processes related to data prep and pipelines
Relentless pace of requests from colleagues
Also key influencers in the data engineering domain raise this concern.

Notice the main reasons above, they are mostly about data quality, manual repetitive work and scalability. Hence, there is no surprise that there are trends trying to address both the gap in demand/supply of data engineers and the main reasons for burnouts.
Trends - Shifts along the data lifecycle
Those trends are mainly about shift of ownership along the data lifecycle, either right/downstream or left/upstream;
Shift-right (downstream): the Modern Data Stack that (at least initially) focused on solving most of the problems with a plethora of services and throwing compute at it in your data warehouse or lake, often through transforms defined in SQL performed by a new (?) role - Analytics Engineer. And before that we could see an even more extreme movement to the right with self-service analytics/BI solutions.
Shift-left (upstream): the Data Mesh (Zhamak Dehghani), a decentralized and data product oriented approach that puts more responsibility on data producers. But also the popularity of data contracts (Chad Sanderson) that tries to address data quality challenges but also improve data literacy and bringing data producers and consumers closer to each other, short-circuiting the communication that previously was done via a data engineer. One way to enable data contracts is through golden paths that enforces these contracts.
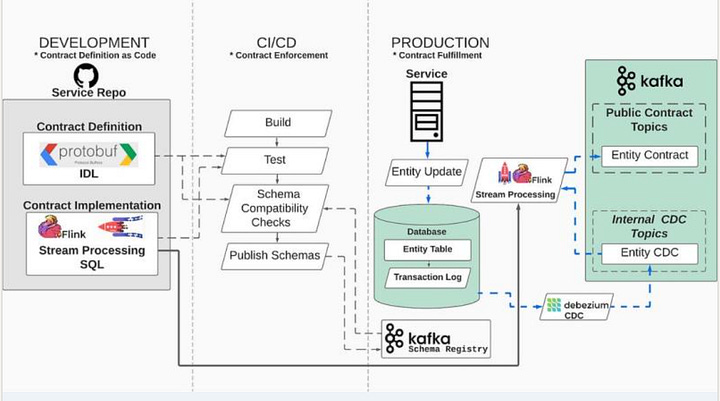

Data Contracts (Chad Sanderson), Data Mesh (Zhamak Dehghani)


Both of them trying to solve speed to insight/action and scalability, but not in terms of data latency and data volume, but eliminating the data engineer as a bottleneck in the data lifecycle.
Data-First stack
I’ve been evangelizing and gradually implementing a shift-left approach with streaming processing and data contracts at the heart, hence the Data First-stack proposed by Animesh Kumar resonates well with me. Two important corner stones in that practice are:
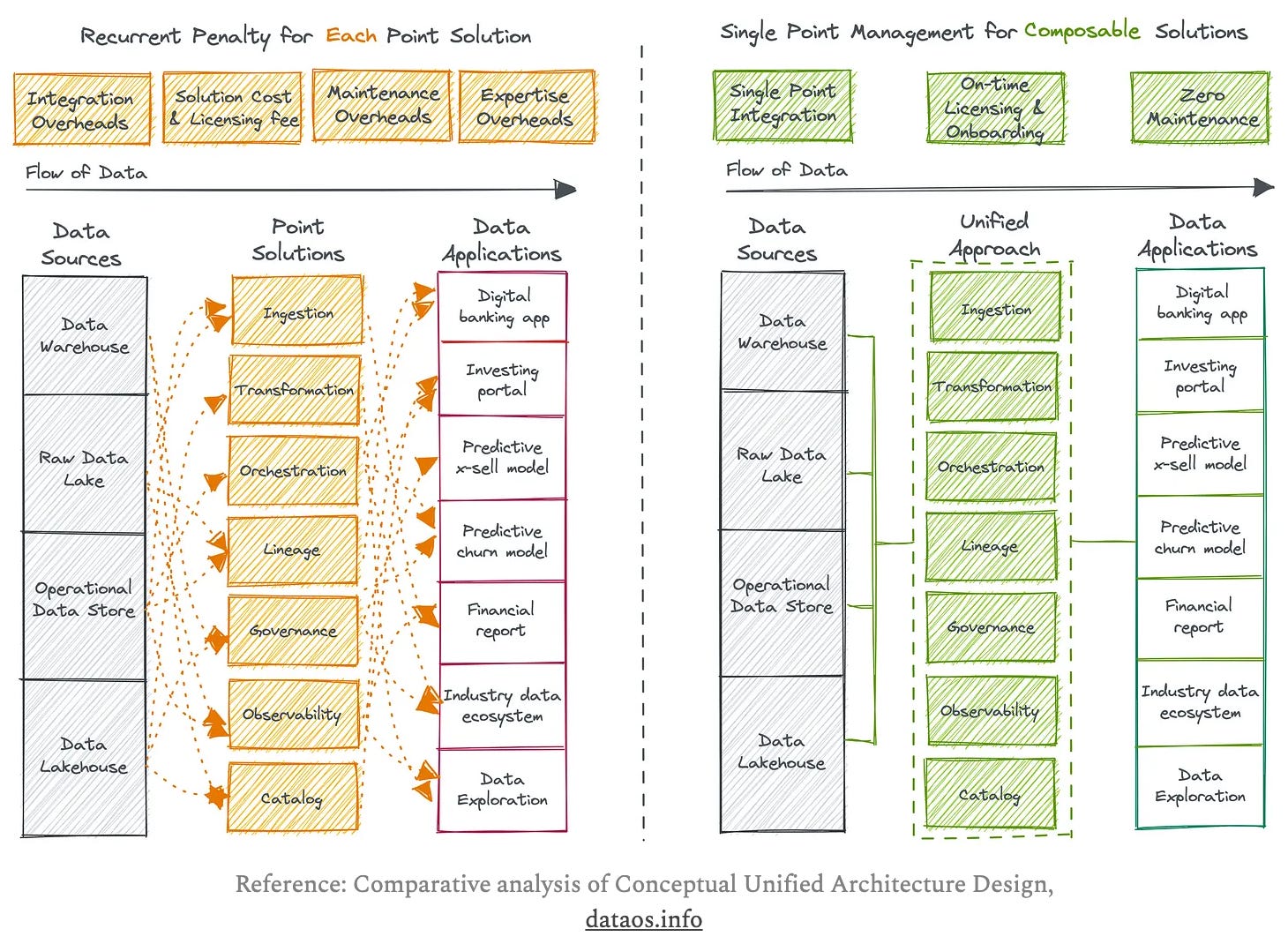
Unified architecture - consists of a small set of core components. These components are put together to form a loosely coupled but unified approach to support multiple and well defined producer and consumer patterns.
Declarative management - using data contracts to manage data quality, governance, security, and semantics. The best part is that contracts enables automation of many steps in the data engineering lifecycle and I’m confident we will see the same pattern also being applied downstream.
Roles along the data value chain
In order to justify my initial statement we’ve briefly gone through the data engineering role, major trends and the data-first stack, but before jumping to a conclusion I want to introduce the data value chain and the associated roles by referring to a great visualization by Aurimas Griciūnas.
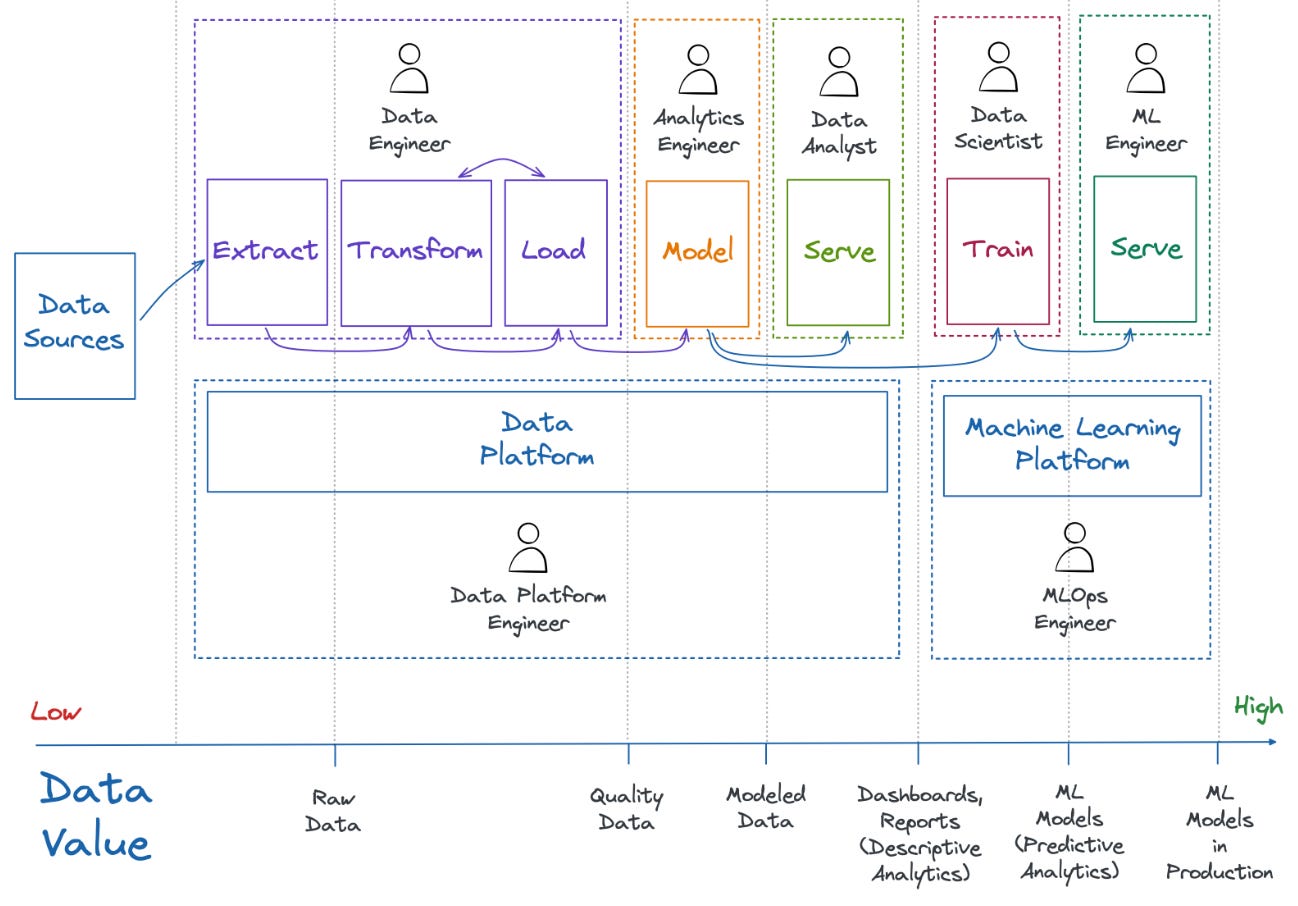
As you can see the data flows from left to right and increases in value along that journey. The Data Engineer sits in the upper left corner and the upper part is very similar to the data engineering lifecycle visualization. However, here we introduce the data platform and MLOps engineers - building and maintaining the data and machine learning infrastructure - remember, the missing piece to leverage value from data science. Notice that these are all roles and could be organized in many ways.
Operational + Analytical systems = True
When developing operational systems it is not uncommon to be organized in cross-functional product teams developing applications and services (products) on top of a common platform/infrastructure that is developed, operated and maintained by an infra/platform team. I see the analytical and the operational systems overlap more and more as the data domain picks up more and more of software engineering best practices, at the same time data is starting to be regarded as a first class deliverable by the operational system and analytical data increasingly is operationalized to enhance customer experience or internal efficiencies.

Hence, I think the analytical teams will align and I won’t be surprised to see analytical roles pivot from a central data team into domain oriented squads working on data powered applications and closing the loop. Hence a tech squad will not only consist of software engineers but also analytics engineers and data scientists. That also enables the data roles to build business domain knowledge while educating software engineers about data and analytics and set early requirements. Such cross-functional teams will be more autonomous, fast-paced and take on full ownership to solve domain oriented business challenges not only with services and applications but also powered with analytical capabilities and data products. Those teams need data engineering to succeed, but data engineers are often a bottleneck when the number of data producers, consumers and use cases increase in an organisation.
Data engineering != Data engineer
The answer to provide more data engineering capabilities isn’t necessarily to recruit more data engineers. We’ve seen product teams taking on more responsibilities before, given the right conditions and support.
In a data-first stack the (data) platform engineers build the unified architecture and with data contracts you can implement declarative management to automate many parts of the data engineering and to some extent also the analytics engineering. The data engineering will shift to data producers (in dialogue with primary data consumers, i.e. analytics engineers) but through data contracts and enabled by the unified data platform. To understand how that shift is enabled by a unified platform I recommend my post about The Golden Path Revolution that details the concept of golden paths.
Hence, letting data engineers pivot into platform engineers not only increase scalability in terms of number of producers, consumers and use cases but also improves time to insight and data quality. It is my experience that it also makes the job more fun to build a platform/product rather than yet another pipeline, but also clear responsibilities and requests from stakeholders.

I also think the same pivoting will happen to ML Engineers, i.e. ML platform engineers building a ML-platform rather than ML-pipelines, and the data and ML-platform teams will be tightly connected if not one and the same as the data product built by the product team runs on top of both platforms. Another reason why I prefer data and ML platform engineers working in the same team rather than two different teams is knowledge sharing, support and on-call that are much easier to provide with bigger bandwidth and a more complete understanding of the data lifecycle for a product.
A data platform engineer becomes more of an infra/software engineer and doesn’t build data pipelines or data models, but provide services, tooling, environments (development, test, production) and support to create a great user experience of a self-serve data platform used by the cross-functional teams. Different roles in the cross-functional team may require different services, tooling and suport to enable them to develop, test and operationalize different data deliverables, ex;
Data pipelines (ingest, store, transform and serve) - SW Engineer
Data models - Analytics engineer
Reports and dashboards - Data analyst
Statistical/ML models - Data scientist
Data feeds / Data activation / Reverse ETL - SW Engineer / Analysts
I want to emphasize that being a platform engineer is not only about data, more importantly it is about providing a great user experience for the platform users, i.e. the cross-functional product teams.
I intend to write a more technical post about the data platform we’ve built at my current employer and go into details about the unified architecture and data contracts used.
Joe and Matt also present scenarios of how the data engineering role may change over time.
https://data.world/industryresearch/data-engineer-survey-2021
Interesting post, I've shared this in my newsletter!
I've too found myself spending most of my time on some Data Platform projects writing Infrastructure as Code for data lakes and databases and networking them together.
Those projects have often had the domain experts building the dashboards themselves: some are like Analytics Engineers doing the modelling and pipelines too, but some just make dashboard and reports based on data presented.
Though I'm not sure I'd want to give up the building of pipelines and dashboards - there something satisfying about building everything needed for a end to end data pipeline, even if it is a bit exhausting to wear too many hats!
I would like to thank all data engineers for their hard work on improving data collecting 😊😇