
From pipelines to platform
Getting value from analytical data at scale

Given earlier posts about data engineering and data flywheels, how can we connect the dots? Slides are from my presentation at Nordic Data Analytics Community Launch Event (October 13).
Getting value from analytical data at scale
I like to think that the ultimate task of a data team is to act catalyst for building and running data flywheels to generate value from analytical data at scale. A data flywheel is a cycle of data-driven activities (generate data, learning, decision, improve experience/process) that feed and are driven by each other to build self-sustaining business momentum.

A data flywheel isn’t that different from a mechanical flywheel in the sense that it takes tremendous effort to put it in motion, but once it picks up speed it almost becomes self-sustaining. The analogy is that the “data team” really has to focus on connecting the technology, process and people to complete the cycle of activities that constitutes the flywheel. That will require time and energy from the data team to complete the first few loops, but as the process starts to set in and people understand how the cycle works and what part they play and how they can contribute and what value it brings - the data team can gradually get out of the way to let tech, product and business take over ownership, i.e. it reaches self-sustaining momentum.
So in the end, creating value from data at scale is all about creating data flywheels and get them spinning as fast as possible.
Why platform over pipelines?
11 years ago Harvard Business Review dubbed data scientist the sexiest job of the 21st Century and I was one of those quickly jumping on that train. But quite soon I realized that something was missing - data infrastructure - and data scientists don’t build or maintain that and provide little value without it. Hence, I jumped off the data scientist hype and made a bet on the lesser known role as data engineer. Fast forward 10 years and now the data engineer is regarded as the hottest job in data. That means it is hard to find and recruit data engineers and those available on the market expect a salary that reflects the market situation.

So the data engineer role is in high demand, but surveys show that the job isn’t as rosy as expected as surveys suggests an overwhelming majority are burned out and calling for relief.
The data engineers surveyed identified significant sources of burnout including:
Spending too much time finding and fixing errors
Manual, repetitive processes related to data prep and pipelines
Relentless pace of requests from colleagues

Looking at the data flywheels (blue arrows below) and the roles involved to complete the flywheels we see that the data engineer not only build the necessary connection between the operational and the analytical system that enable learning and decision making, but all to often acts as a repeater of questions and answers between data producers and consumers. Also, the data engineer often is formally or implicitly assigned the ownership of data quality. Hence, the data engineer is a bottleneck in more than one aspect.
As a reaction we see trends that try to address the bottleneck and shift ownership along the data lifecycle, either right/downstream or left/upstream;

Shift-right (downstream): the Modern Data Stack that (at least initially) focused on solving most of the problems with a plethora of services and throwing compute at it in your data warehouse or lake, often through transforms defined in SQL performed by a new (?) role - Analytics Engineer.
Shift-left (upstream): the Data Mesh, a decentralized and data product oriented approach that puts more responsibility on data producers.
You can’t scale data engineers
So why do I bring up the limited availability of data engineers, a role facing many challenges and often a bottleneck when building the pipelines essential for data flywheels?
Because we can’t scale data engineers to match the ever increasing data producing systems, the growing number of data consumers and use cases.

Scale data engineering with a data platform
We can’t scale data engineers, however we can scale data engineering. The key to remove dependency on data engineers is to automate and facilitate communication between data producers and data consumers. The way we have approached this at Mathem is to pivot the data engineering team into a data & ML-platform team and build the data infrastructure to offer a great data product developer experience to stakeholders along the data flywheel. Two key components are Unified Architecture and Declarative Management (also known as data contracts) in order to enable automation and communication around data streams.

Declarative Management
This is an example of a data contract we use at Mathem, it is defined with YAML and consists of different sections. This particular contract is related to product proposals submitted by Mathem customers that helps us update the assortment that we keep in stock. As you can see it defines both the source and target (BigQuery tables) where we also can define what kind of models we want to build in our silver layer (we have a medallion architecture) to be ready for downstream consumers. It also defines ownership and makes it clear what squad that owns this data asset and where you find the repo of service that is the origin of the data. We also have the schema and some optional sections not shown. The schema follows BigQuery schema definition as that is our major target destination and to the right you see the replica table created from this contract.

Data quality by enabling communication & validation
The process for creating and publishing a contract is a vehicle for both communication and validation which is essential in order to remove the data engineer as a bottleneck. When a data producer makes a PR of a data contract a number data consumer teams will be notified for a review. The dialog is about things like descriptions, data types and whether a field is required or nullable. But also what fields constitute primary and sort keys and what kind of models consumers want generated. The PR will also trigger a number of validation checks that not only check if the contract is valid according to the data contract specification but also if a sample of payloads pass the contract verification.

There is also a lot of dialogue between team members within the data producing squad and the contracts are not only valuable for the analytical system as we’ve seen it is a great tooling also to verify the data quality in the operational system as many of our micro services use a schemaless storage layer (dynamodb).
Unified Architecture
The other central piece is to ensure you have a small set of core components, i.e. a unified architecture. These components are put together to form a loosely coupled but unified approach to support multiple and well defined producer and consumer patterns.

Here you see that we support a number of mechanism to ingest data into our data platform and a few options to output data. But the components in between are the same and that keeps down operational cost and maintenance but also makes it easier for the team to master all parts of the data platform regardless source or destination.
The ingest is for example a streaming architecture, so if a file is uploaded to GCS then it trigger an event that will execute a cloud function that reads the data and publish it to the pubsub topic for processing by dataflow. The transform is a fastAPI application on cloud run that executes our DBT models according to a schedule defined in the data contract mentioned earlier. This is also part of a review process and with checks, test environment, CI/CD etc. The export is also a service provided by the data platform team where the logic is defined in DBT and the actual export is event-driven with the help of GCS, cloud functions and workflows. Ingest, transform and export all follow the same idea of enabling stakeholders to be autonomous and own the business logic and data quality while we provide the systems, tooling and support to offer a great developer experience and an efficient process.
Automate, automate, automate…
Let’s look closer att the data ingestion and the smallest of the data flywheels mentioned in the beginning - operational analytics. The new data ingestion solution we have been developing to support our new responsibility as a data platform team works like this.
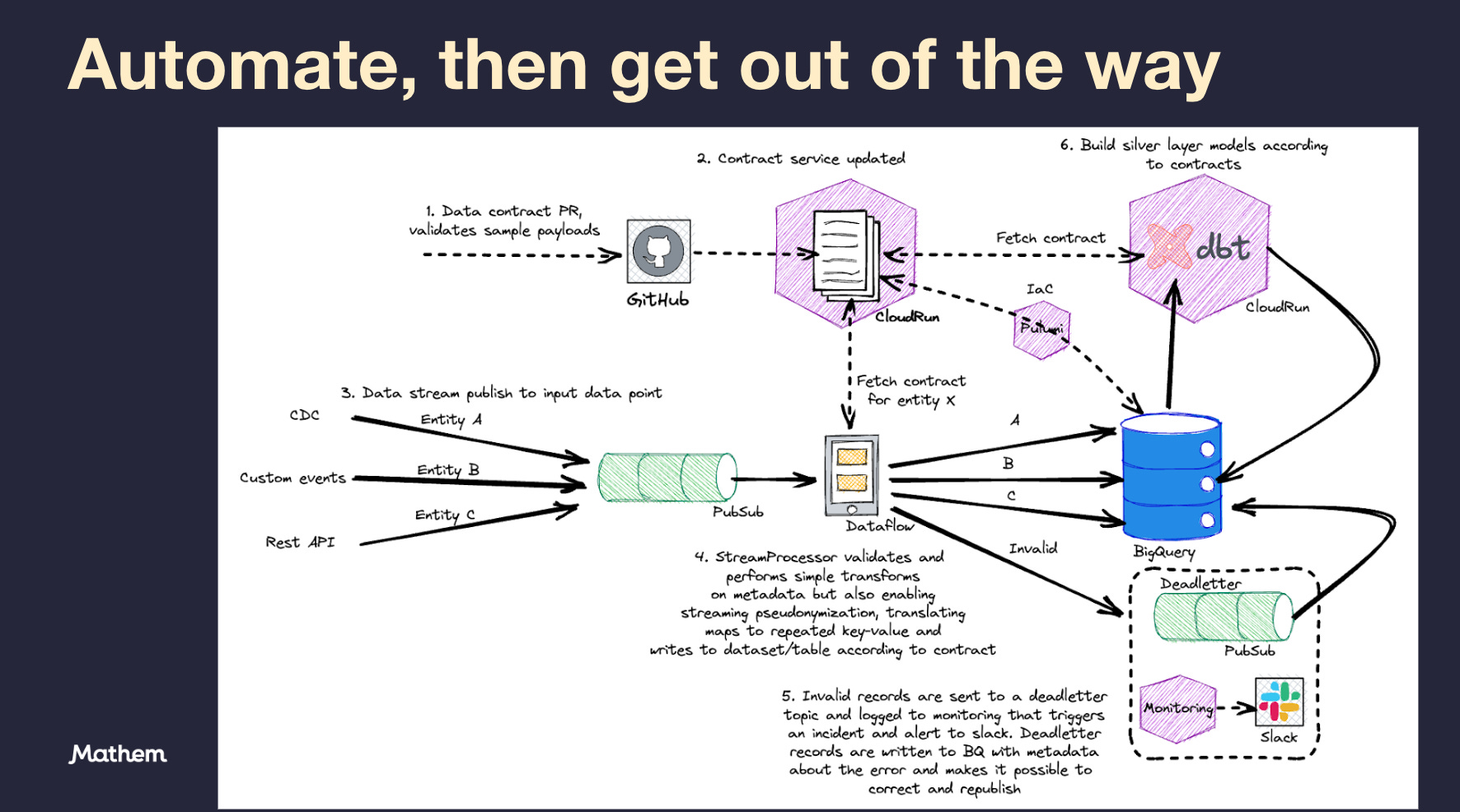
A squad makes a data contract PR and when it is approved and pass all checks it gets merged and the data contract service (fastAPI on Cloud Run) is updated accordingly and our Infrastructure as Code (Pulumi) will set up the corresponding staging tables in BigQuery. The merge will also generate a PR in the DBT repo to generate the silver layer models defined by the data contract.
The squad ingest data via one of the supported input data ports and the data land on pub/sub where it is processed by our dataflow job called StreamProcessor. The job can process data of different entities and pick up the entity from the message attributes and fetch the contract from the contract service if it isn’t cached by the dataflow worker (the cache default expiration is 5 minutes). This means that we can add new streams at any point and we don’t have to re-deploy the job. The job will parse and serialize the payload according to the contract. We have a few features such as supporting maps by transforming it to a bigquery supported repeated key-value format. Another is that we enrich the message with metadata that is stored in a _metadata RECORD. Lastly, it also routing messages to the dataset and table defined as targets by the contract.
If a message payload doesn’t comply with the contract it is enriched with the error message and published to a deadletter topic and written to a BigQuery deadletter table and alert what entity that has failed to be parsed so that proper action can be taken.
This is all streaming and data is available for analysis within 2-5 seconds from when data reach one of our input data ports. I often see real-time analytics being laughed at as providing little or no value, but at mathem we have use cases that requires high data freshness.
Platform adoption = self-sustaining momentum
To sum it all up, how does a data platform generate value at scale? As any platform the key metric is adoption.
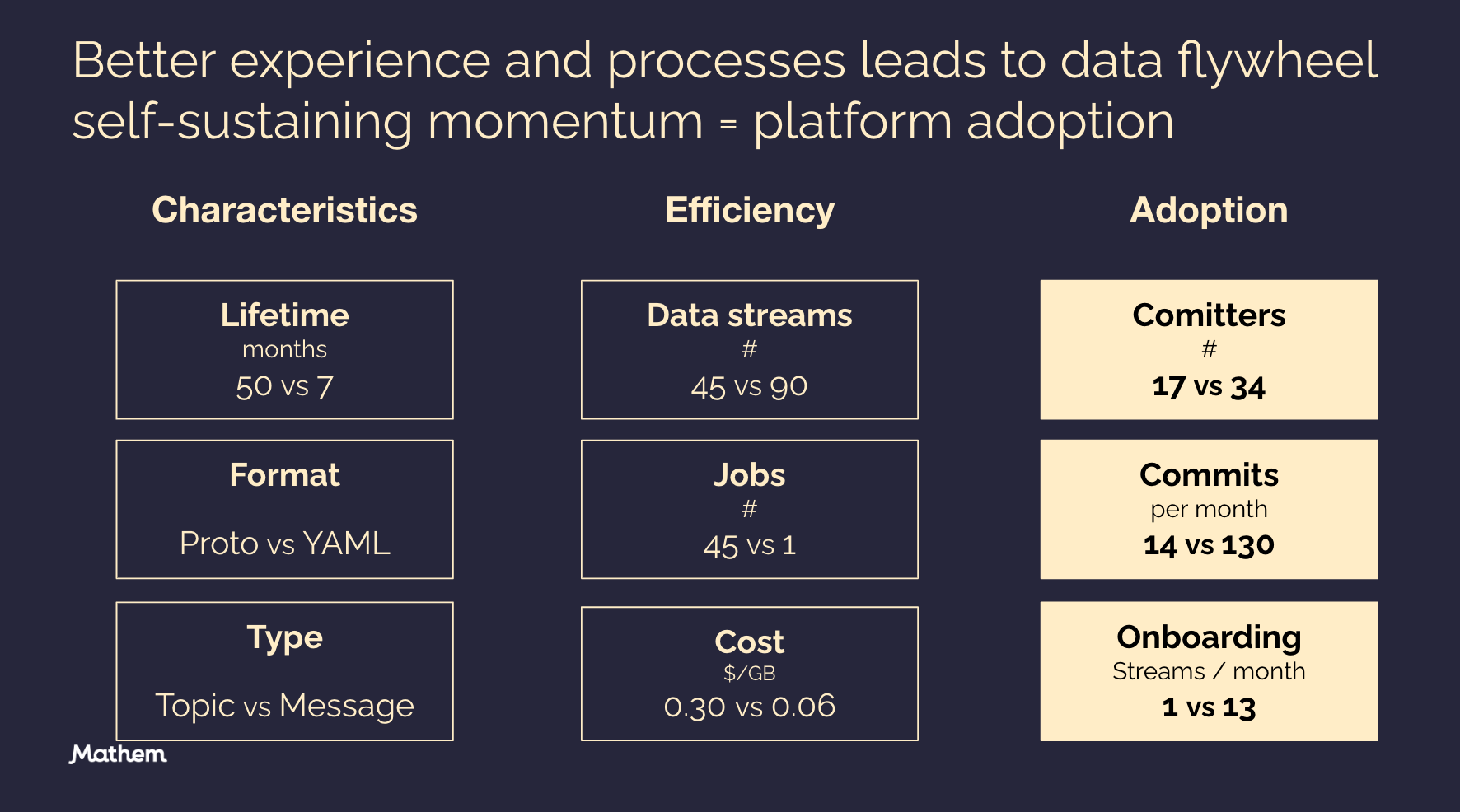
In this example we can see that after running our new ingestion service for 7 months we got twice as many data streams onboarded while running only one job instead of 45 which not only reduce the maintenance and operational overhead but also cost due to much better resource utilization. But the most positive of them all is the adoption of the solution amongst our data producers and consumers. We have twice the number of committers, the activity is 10x (!) and we have onboarded one stream every second workday in average. However, as much it signal success for the new solution and data platform ways of working, it also tells a story about how an inadequate solution slows down adoption and that you will never reach flywheel self-sustaining momentum unless your stakeholders are offered a great experience and efficient process.
Do you have good examples of good or bad data flywheels you have seen in your career as a data professional?
What do you think about data flywheels as a model to generate value from analytical data?
I'm committed to keeping this content free and accessible for everyone interested in data platform engineering. If you find this post valuable, the most helpful way you can support this effort is by giving it a like, leaving a comment, or sharing it with others via a restack or recommendation. It truly helps spread the word and encourage future content!