
The Madness of Data Incident Management
Context Switching as an Analytics Engineer On-Call

If you’ve ever been on call as an analytics engineer, you know the chaos all too well. You're deep into a transformation in dbt, focused and productive, when suddenly, your workflow gets shattered by an alert from OpsGenie—something broke, and it’s your responsibility to fix it. Now, the real madness begins: context switching between a maze of tools and systems while racing against time to resolve the issue, communicate with stakeholders, and prevent further fallout.
As someone who’s been on both sides of this—both as an individual contributor and a manager—I know firsthand how stressful and overwhelming this can be. Incident management in the data space is rarely a task that engineers enjoy, and it often brings more stress than satisfaction.
Navigating Tool Overload
The moment an alert hits, you might find yourself bouncing between systems: dbt to check the transformation, Airflow to inspect the job that orchestrated the pipeline, and then over to Cloud Monitoring to ensure there’s no underlying infrastructure problem. Meanwhile, you’re fielding Slack messages from anxious data consumers and jumping into OpsGenie to track the incident.
Maybe the root cause is a schema change upstream that broke a transformation. Or maybe it’s a subtle issue in your models. Regardless, it’s going to require patching code, so off to GitHub you go to create a pull request for the fix. And don't forget to update the on-call rotation log and ticket in OpsGenie to keep everyone informed on progress.
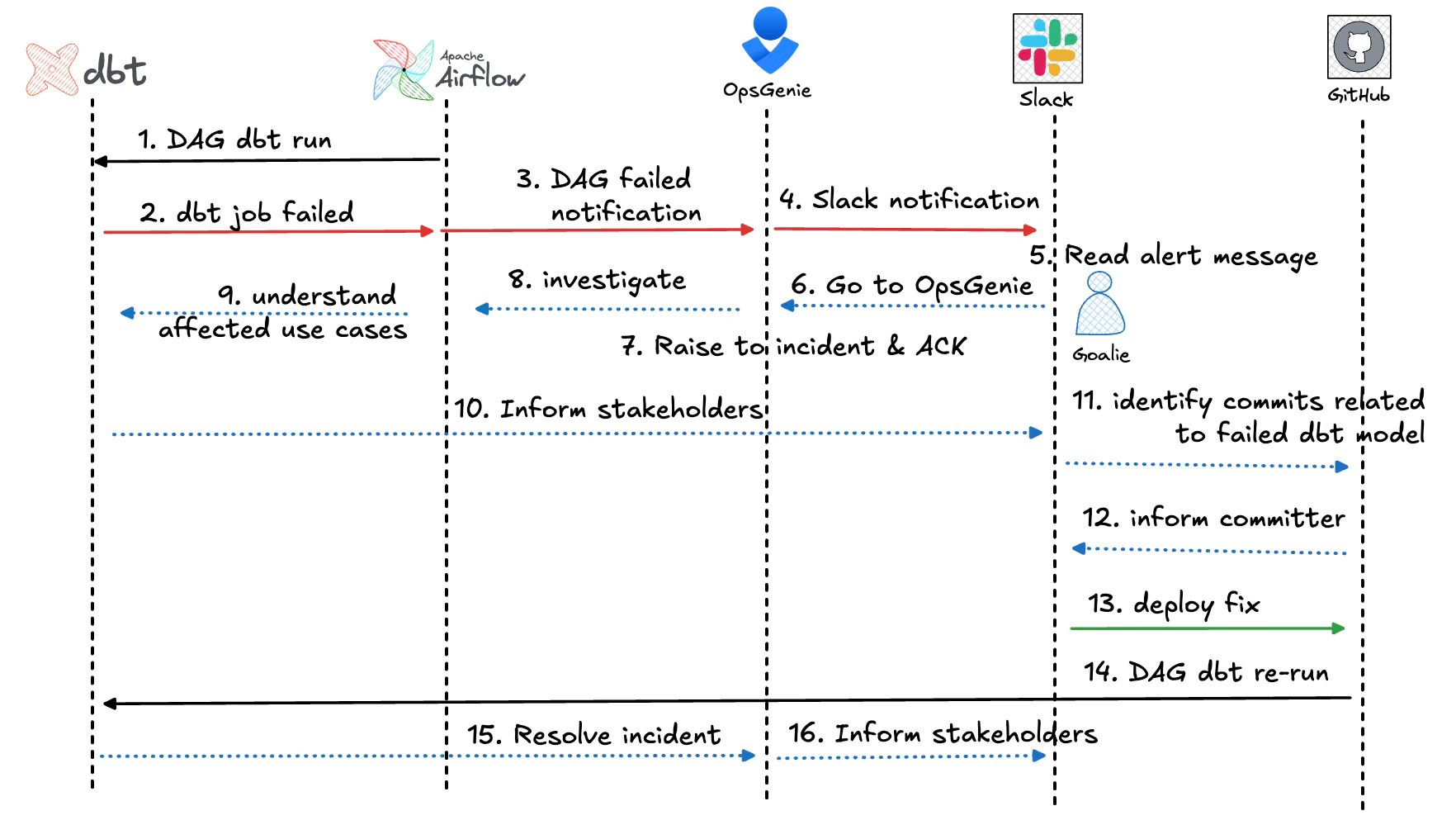
Juggling multiple platforms is mentally draining, and the tools don't naturally fit together. You end up as the human glue, stitching everything into a cohesive process.
The Struggle with Lineage and Ownership
A major challenge in these incidents is the lack of data lineage. You might identify the immediate issue—perhaps a dbt model broke—but what about its cascading impact? What dashboards or reports depend on this transformation? What data consumers need to be notified immediately? Without clear lineage mapping, understanding the impact becomes a guessing game.
Equally problematic is figuring out ownership. Who owns the upstream data source causing the problem? Are they aware? Do they know that the issue is theirs to fix? It’s often difficult to get clarity on who should take action, leaving you as both the investigator and communicator.
Prioritizing Incidents Under Pressure
Not all data incidents are created equal. A failure that impacts an internal report isn’t as urgent as one that affects a customer-facing product or revenue-driving system. But when multiple alerts come in, determining what needs immediate attention can be challenging. The typical tools used for monitoring and alerting don’t always provide the necessary business context, so you end up treating every alert like a fire—whether it’s a spark or a blaze.
Onboarding New Engineers into This Madness
Now imagine being a new hire. You’re thrown into this incident management world where so much of the process is informal and learned through experience. There’s often very little documentation about previous incidents, how they were handled, and how problems were solved. The silent knowledge of how to navigate all these tools, manage priorities, and communicate effectively with stakeholders takes time to build, which can increase the pressure on both the new engineer and the team. Without proper documentation or a clear process, onboarding new team members becomes another source of stress.
A Pain I Know All Too Well
I've lived through this madness. As an analytics engineer and a manager, I’ve experienced the frustrations of constant context switching, juggling disconnected tools, and trying to resolve critical incidents while ensuring everyone is informed. It’s not an ideal situation, and it adds stress to a role that is already demanding. I know the pain firsthand, and it’s something no one on an engineering team enjoys.
Moving Towards a Solution
If any of this resonates with you, know that you’re not alone. The challenges of incident management—tool overload, lack of lineage, ownership confusion, and prioritization—are common. There are solutions out there that address these pain points, and if you're interested in discussing how to streamline this process, please don’t hesitate to reach out. Whether you’re an individual contributor or a manager, improving incident management can make a world of difference for your team and your sanity.
What About You?
I’d love to hear from you—how has your experience been with managing data incidents? Have you implemented any processes, tools, or solutions that have worked well for your team? If you’ve found a way to tame this chaos or have best practices to share, feel free to drop a comment or reach out. Sharing our collective experiences is the best way to move forward in tackling these challenges together.
I'm committed to keeping this content free and accessible for everyone interested in data platform engineering. If you find this post valuable, the most helpful way you can support this effort is by giving it a like, leaving a comment, or sharing it with others via a restack or recommendation. It truly helps spread the word and encourage future content!
Good read.
Been part of couple of large data teams at one of the Magnificent 7, each serving orgs running tens of billions of dollars in revenue and owning hundreds of mission critical core workflows and data products.
What did I learned?
Trying to get a full control of deep data lineages is a lost battle. Too much entropy to hope for a clean and deterministic system.
Fixing the common root cause of recurring issues is a must, but not always realistic (at least in short term).
Instead, most effective way is to persist the tribal knowledge and make it easily accesible (searcheable) by people under duress:
* In the incident ticket, document each step done in the investigation and in what have been done in fixing and testing (can be done postmortem).
* Comment the code with common sense plain English to be understood by someone who just been pages at 3:00 am (a priority in code commit review)
* Have written standard operation procedures for each main category of incidents; revise them oftenly (core part of each sprint review)
* VERY IMPORTANT: Make sure that all this persisted tribal knowledge is searchable, ideally from one place (never tried, but I guess tuning an off the shelf decent LLM with your code and history of incidents would be very cool)
* MOST IMPORTANT ( AND THE HARDEST ONE):
Encourage all your team buddies to do due diligence in writing all the stuff above.
My experience is this takes time (6 months to 1 year). You start with yourself doing the extra work on each oncall rotation and let people see how useful it is that - at 2 am - to find that 80% of your problem was very similar with another one which happened few months ago.
Nice read! I'm wondering, though -- apart from the tools, what aspects of this are actually data-specific, and what are simply the challenges of software incident management? If, say, the application's transactional database starts getting hosed (and you don't know why), aren't engineers forced to do basically the same process?