

July 28, 2022 Google released BigQuery subscriptions in Pub/Sub to write messages directly to an existing BigQuery table. It supports use of topic schema (avro or protobuf), but if you don’t then it writes data to a schema that at the time of writing looks like below.

It doesn’t support JSON type
As you can see data is defined as BYTES/STRING and attributes is defined as type STRING despite the data being represented as a json object. I think the message data quite often is JSON and hence unfortunate that BigQuery subscriptions don’t support the native JSON data type for data and attributes.
Or does it?
I figured I would give it a try as I suspect that JSON support has been a prioritized feature on the roadmap, hence I defined two tables, one as the documentation above and one with the same fields but with type JSON instead of STRING and gave it a try.

I published a message with data {"firstname":"john","lastname":"Doe"} and attributes {"hello":"world"} and if I query my table you see that row in the table.

Let’s test that we can select json values in the data and attributes fields to confirm that it really works.
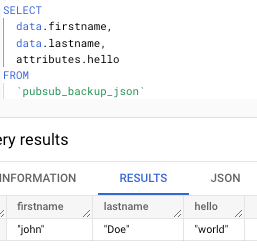
And it does! Seems like Google has deployed support for JSON data types without officially releasing it, I expect it to be announced any day/week. Sorry for breaking this in advance :)
Anyway, nice to see the support for JSON fields, one thing I miss is the possibility to configure a field (either in data or attributes) that could be used for clustering since that would make this solution great for a generic backup table that contains data from many different entities but at the same time avoiding scanning data from all entities when doing a backfill on a specific entity.